


Mysql索引底层数据结构与算法
1、数据结构可视化网站
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html

2、数据结构
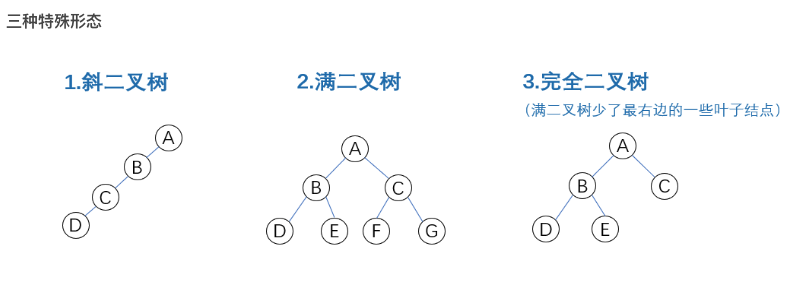
2.1 二叉树(Binary Tree)
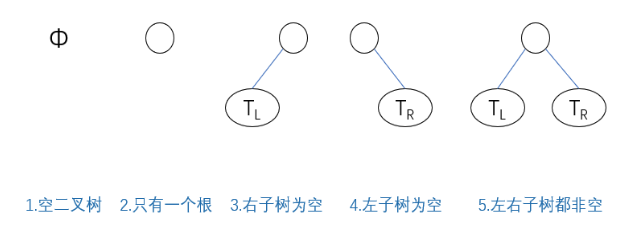
二叉树(Binary Tree) 是由n个结点构成的有限集(n≥0),n=0时为空树,n>0时为非空树。对于非空树T:
- 有且仅有一个根节点
- 除根节点外的其余节点又可以分为两个不相交的子集T与R,分别称为T的左子树与右子树,且T与R本身又都是二叉树
- 同高度的右树的数据比左树的数据大
2.2 红黑树
红黑树是会平衡的二叉树,平衡二叉树会绝对平衡,红黑树会相对平衡。
2.3 Hash表
- Hash
- 对索引的key进行一次hash计算就可以定位数据存储的位置
- 很多时候Hash索引要比B+Tree树索引更高效
- 仅能满足“=”,“IN”,不支持范围查询
- hash冲突问题

2.4 B-Tree
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排序
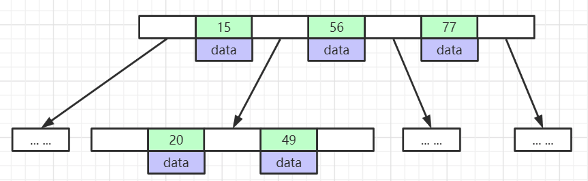
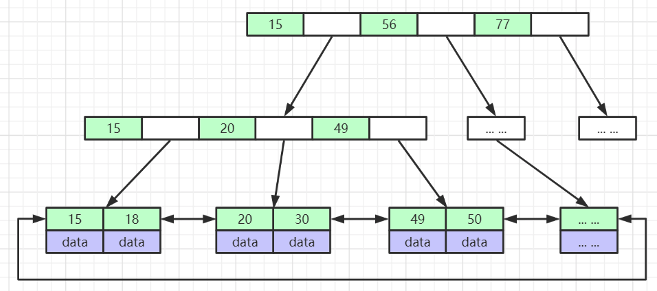
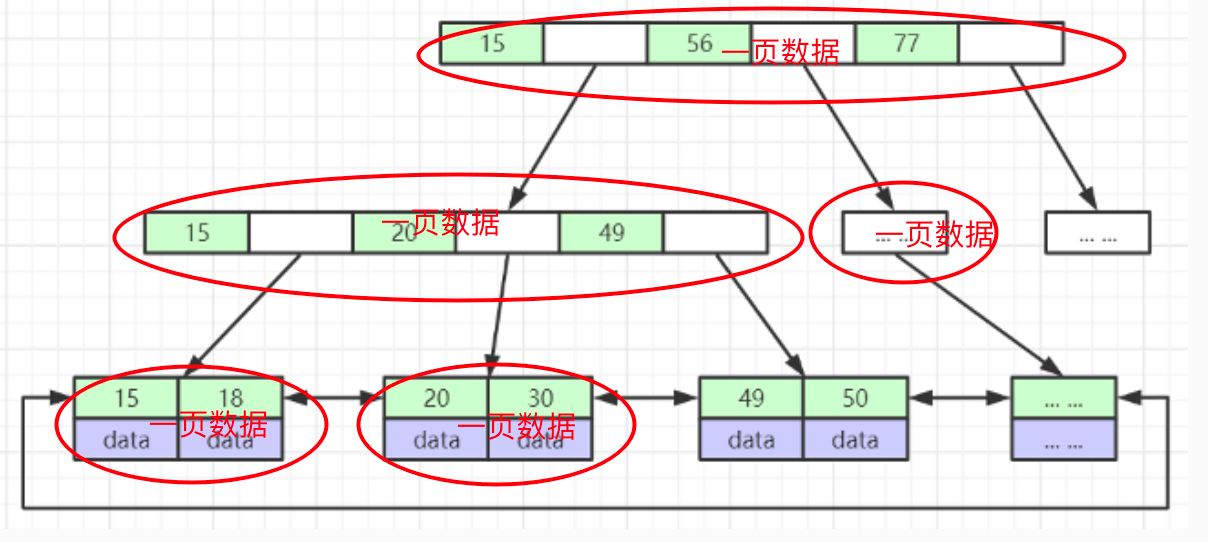
2.5 B+Tree(B-Tree变种)
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能
- 每页最多存储16KB数据
- 每一条索引记录当中都包含了当前索引的值 、 一个 6字节 的指针信息 、一个 5 字节的行标头,用来指向下一层数据页的指针
- 最少存放记录数:最大行长度略小于数据库页面的一半,之所以是略小于一半,是由于每个页面还留了点空间给页格式 的其他内容,所以我们可以认为每个页面最少能放两条数据,每条数据略小于8KB。如果某行的数据长度超过这个值,那InnoDB肯定会分一些数据到 溢出页 当中去了,所以我们不考虑。
- 阿里的Java开发手册上也提出:单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
3、索引的本质
- 索引是帮助Mysql高效获取数据的排好序的数据结构。
- 索引的数据结构
- 二叉树
- 红黑树
- Hash表(Mysql索引真正的数据结构,数据结构见2.3)
- B-Tree
- B+Tree(Mysql索引真正的数据结构,数据结构见2.5)
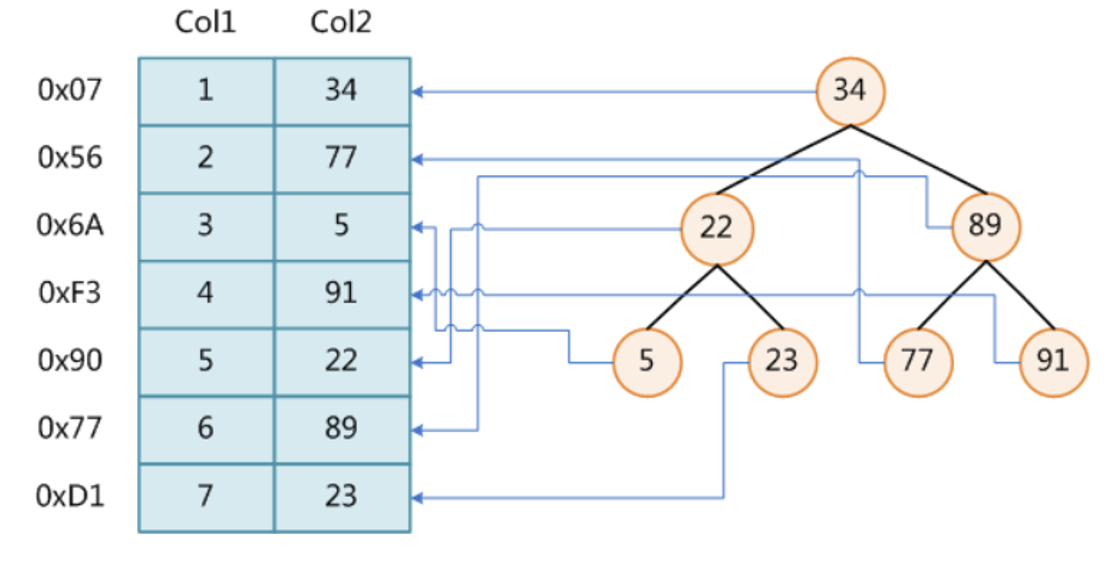
3.1 Mysql不使用二叉树作为索引的原因
索引的查询效率在于树结构的深度,树越深查询的次数越多,IO操作越多,越费时。
3.2 索引方式
MySQL数据库中常用的索引方式为B+Tree索引、Hash索引,而B+Tree索引可以分为聚集索引(聚簇索引)和非聚集索引(非聚簇索引)。
3.3 聚集索引(聚簇索引)
- 聚集索引:索引项的排序方式和表中数据记录排序方式一致的索引(如字典的拼音目录就是聚集索引,它按照A-Z排列,实际存储的字也是按A-Z排列的)
- 每张表只能有一个聚集索引
- 聚集索引的叶子节点存储了行记录的全部数据
3.4 非聚集索引
- 非聚集索引:索引的逻辑顺序与磁盘上行的物理存储顺序不同
- 一个表中可以拥有多个非聚集索引
- 叶子节点并不存储行记录的全部数据,而是存储数据的位置信息。
4、索引类型
MySQL目前主要有以下几种索引类型:普通索引、唯一索引、主键索引、组合索引、全文索引
4.1 普通索引
- MySQL中最基本的索引,它没有任何限制
- 允许在定义索引的列中插入重复值和空值,纯粹是为了查询数据更快一些。
普通索引有以下几种创建方式:
(1)直接创建索引
CREATE INDEX index_name ON table(column(length));
(2)修改表结构的方式添加索引
ALTER TABLE table_name ADD INDEX index_name ON (column(length));
(3)创建表的时候同时创建索引
CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER NOT NULL , `content` text CHARACTER NULL , `time` int(10) NULL DEFAULT NULL , PRIMARY KEY (`id`), INDEX index_name (title(length)));
4.2 唯一索引
- 索引列的值必须唯一,但允许有空值。
- 如果是组合索引,则列值的组合必须唯一
唯一索引有以下几种创建方式:
(1)创建唯一索引
CREATE UNIQUE INDEX indexName ON table(column(length));
(2)修改表结构
ALTER TABLE table_name ADD UNIQUE indexName ON (column(length));
(3)创建表的时候直接指定
CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER NOT NULL , `content` text CHARACTER NULL , `time` int(10) NULL DEFAULT NULL , UNIQUE indexName (title(length)));
4.3 主键索引
- 是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。
一般是在建表的时候同时创建主键索引:
CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) NOT NULL , PRIMARY KEY (`id`));
4.4 组合索引
- 在表中的多个字段组合上创建的索引,只有在查询条件中使用了创建索引时的第一个字段(即左边字段)时,索引才会被使用
- 使用组合索引时遵循最左前缀匹配原则
组合索引的创建方式:
ALTER TABLE `table` ADD INDEX name_city_age (name,city,age);
4.5 全文索引
- 主要用来查找文本中的关键字,而不是直接与索引中的值相比较。
- 通过文本中的某个关键字,就能找到该字段所属的记录行。
全文索引的创建方式:
CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER NOT NULL , `content` text CHARACTER NULL , `time` int(10) NULL DEFAULT NULL , PRIMARY KEY (`id`), FULLTEXT (content));
5、索引结构
5.1 Mysql两种主要的储存引擎
- MySQL两种主要的存储引擎为:MyISAM 和 InnoDB(5.5版本后默认使用的引擎)
- MyISAM是一种高速引擎,拥有较高的插入、查询速度, 空间和内存使用比较低。如果表主要是用于插入新记录和读取记录,可以选择MyISAM,不过MyISAM不支持事务 。
- InnoDB支持事务和行级锁定,支持崩溃修复能力和并发控制。如果需要频繁的更新、删除操作的数据库,可以选择InnoDB,不过InnoDB比MyISAM处理速度稍慢。
5.2 回表概念
通俗的讲就是,如果索引的列在 select 所需获得的列中(因为在 mysql 中索引是根据索引列的值进行排序的,所以索引节点中存在该列中的部分值)或者根据一次索引查询就能获得记录就不需要回表,如果 select 所需获得列中有大量的非索引列,索引就需要到表中找到相应的列的信息,这就叫回表。
5.3 MyISAM引擎的索引结构
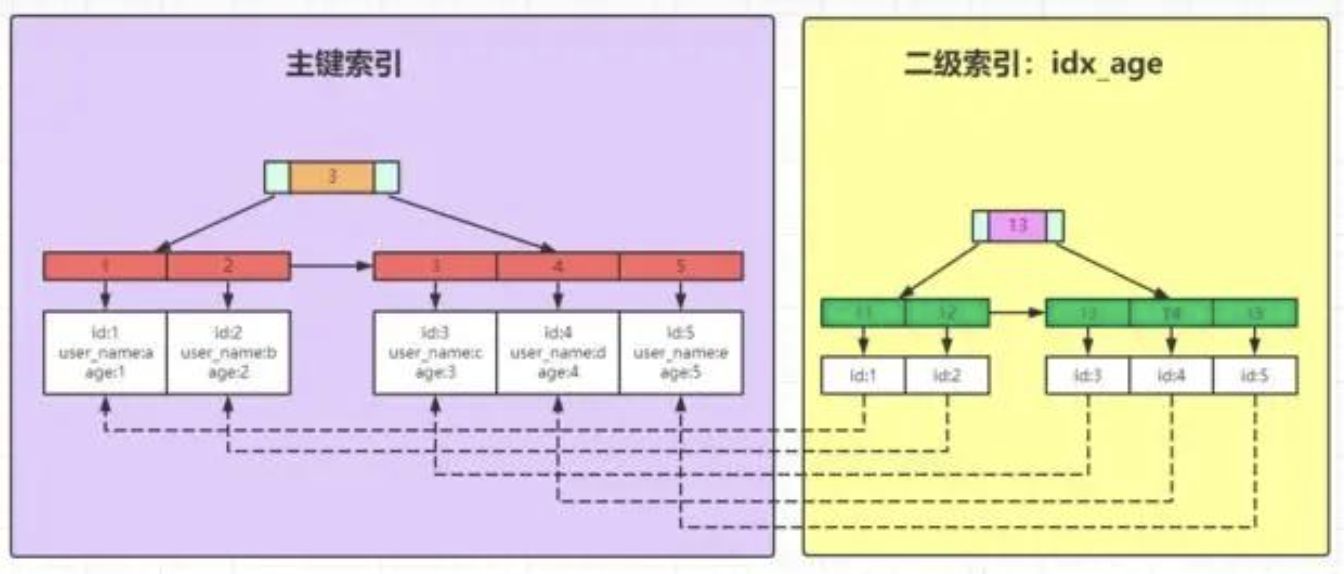
- MyISAM引擎使用B+Tree作为索引结构,叶子节点中存储数据行的物理地址(data域存放的是数据记录的物理地址),索引信息存放在.MYI文件中,具体数据存放在.MYD文件中 ,通过索引查询到对应数据的地址后,需要通过地址在.MYD文件中查询具体数据,及需要回表。
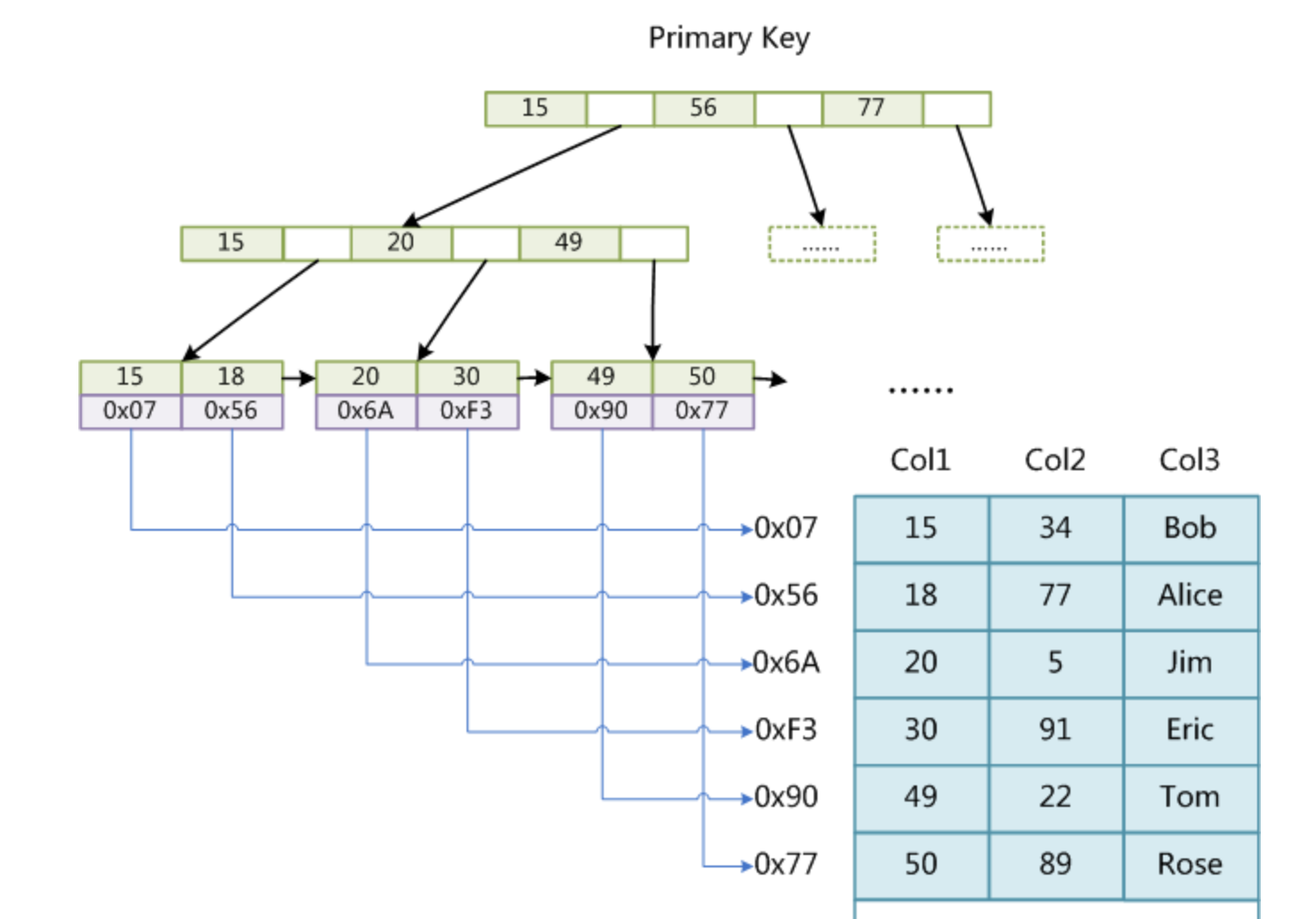
- 在MyISAM中,主键索引和辅助索引(Secondary key)在结构上没有任何区别,都使用的是非聚集索引,只是主键索引要求key是唯一的,而辅助索引的key可以重复。
- MyISAM引擎数据文件结构
- .frm文件存储的是表结构
- .MYI存储的是索引信息
- .MYD文件存储的是表中的数据信息

5.4 InnoDB引擎的索引结构
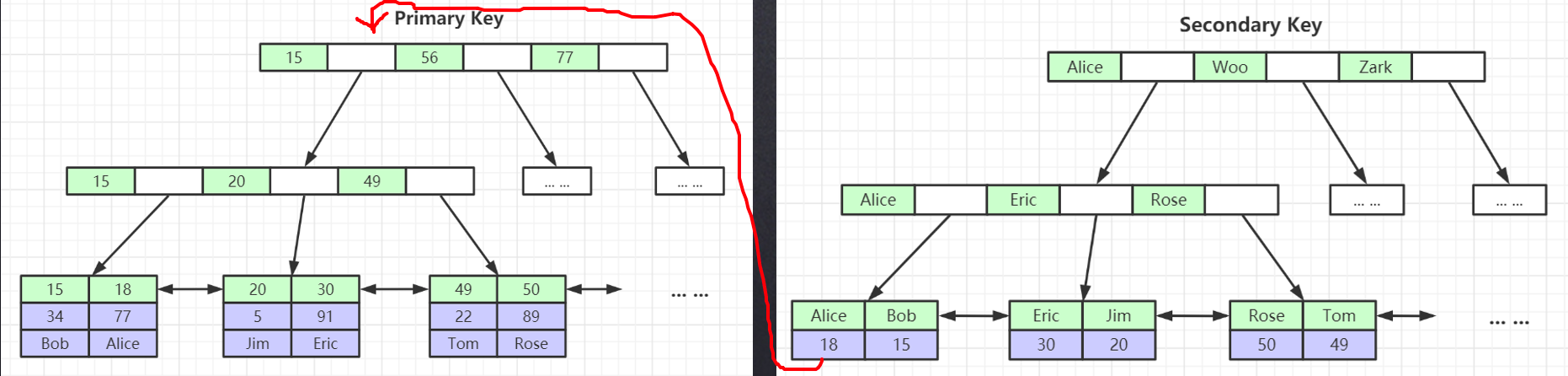
- InnoDB引擎也是使用B+Tree作为索引结构,与MyISAM索引和数据分开存放不同的是,InnoDB引擎数据文件本身就是一个索引。
- 在InnoDB中, 存在有一个主键索引(聚集索引)和辅助索引(非聚集索引)两种索引。
- 主键索引是在生成主键时就有的索引,它的叶子节点包含全部的数据信息;辅助索引就是我们人为新建的索引,它的叶子节点存放的是主键信息。
- InnoDB的普通索引,实际上会扫描两遍:第一遍先由普通索引找到主键,在通过回表的方式,第二遍再由主键找到行记录。
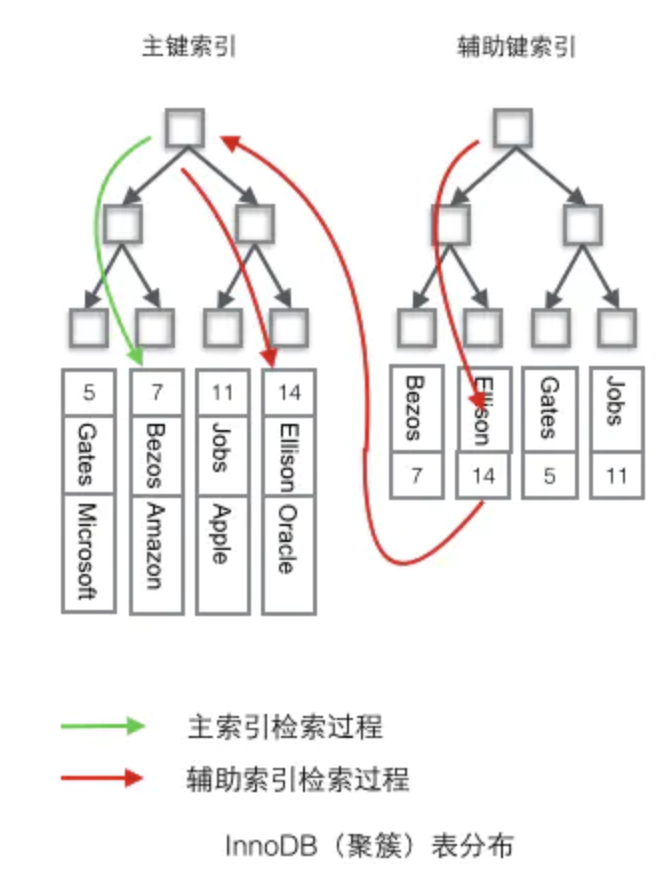
对于InnoDB,当一个表没有主键,或者没有一个索引,有如下规则: - 如果一个主键被定义了,那么这个主键就是作为聚集索引。
- 如果没有主键被定义,那么该表的第一个唯一非空索引被作为聚集索引。
- 如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,该列的值会随着数据的插入自增。
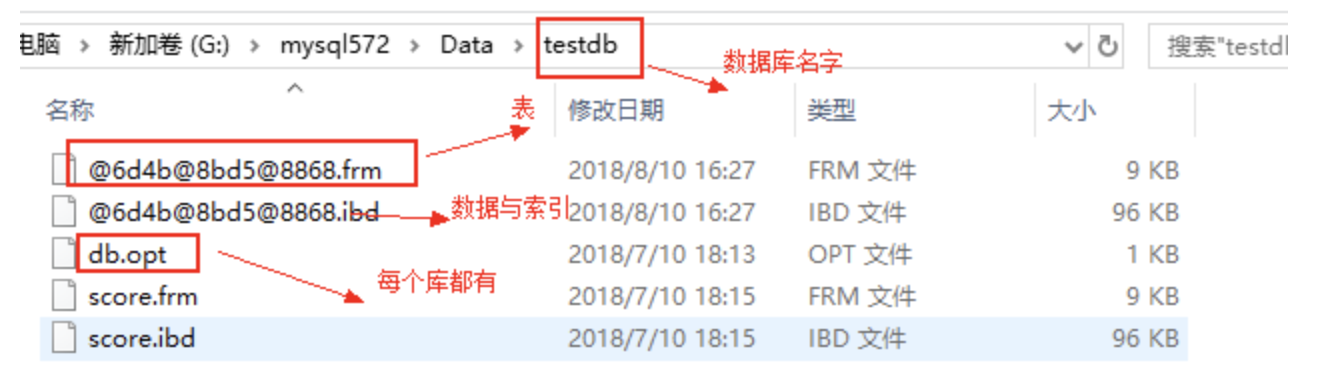
- InnoDB引擎数据文件结构
- .frm文件存储的是表结构
- .ibd文件存储的是索引与表数据
6、注意事项与索引优化技巧
6.1 注意事项
- 执行查询时,MySQL一次只能使用一个索引
- 索引提高了查询速度,但是降低了更新速度
6.2 索引优化技巧
- 使用自增ID做PAIMARY KEY,业务主键做UNIQUE KEY
- 越小的数据类型通常更好:越小的数据类型通常在磁盘、内存、CPU缓存中都需要更少的空间,处理起来更快。
- 简单的数据类型更好:整数数据相比字符,处理开销更小,因为字符串的比较更复杂。
- 一般来说,status、type这类枚举值很少的字段,不适合单独作为索引字段。
- 索引并不是越多越好,无用的索引要删除,避免冗余的索引
- 查询过程中不要使用 LIKE "%aaa%"两端模糊匹配,会导致索引全扫描
6.3 使用EXPLAIN查看执行语句的概况
使用SQL语句进行查询操作时,可以使用 EXPLAIN 这个命令来查看一下SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描等信息。
--实际SQL,查找用户名为mike的员工--
SELECT * FROM employee WHERE name = 'mike';
-- 查看SQL是否使用索引,前面加上EXPLAIN即可--
EXPLAIN SELECT * FROM employee WHERE name = 'mike';
执行结果如下所示:

EXPLAIN 出来的信息有10列,分别是id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra
- id:选择标识符
- select_type:表示查询的类型
- table:输出结果集的表
- partitions:匹配的分区
- type:表示表的连接类型
- possible_keys:表示查询时,可能使用的索引
- key:表示实际使用的索引
- key_len:索引字段的长度
- ref:列与索引的比较
- rows:扫描出的行数(估算的行数)
- filtered:按表条件过滤的行百分比
- Extra:执行情况的描述和说明
评论区